Una nuova ricerca evidenzia che le risposte possono variare significativamente a seconda del modello di intelligenza artificiale a cui si pongono le domande, offrendo risposte più orientate a destra o a sinistra.
Le aziende dovrebbero avere responsabilità sociali o esistono solo per generare profitti ai loro azionisti? Se si pone questa domanda a un’intelligenza artificiale, le risposte potrebbero essere molto diverse a seconda del modello utilizzato. I vecchi modelli GPT-2 e GPT-3 Ada di OpenAI tenderebbero a sostenere la prima affermazione, mentre GPT-3 Da Vinci, il modello più avanzato dell’azienda, concorderebbe con la seconda.
Questo perché i language models dell’intelligenza artificiale contengono diversi bias politici, come spiega una nuova ricerca dell’Università di Washington, della Carnegie Mellon University e della Xi’an Jiaotong University. I ricercatori hanno testato 14 language models di grandi dimensioni e hanno scoperto che ChatGPT e GPT-4 di OpenAI erano più inclini verso il libertarismo di sinistra, mentre LLaMA di Meta era più incline verso l’autoritarismo di destra.
I ricercatori hanno interrogato i language models su varie questioni, come il femminismo e la democrazia, utilizzando le risposte per posizionarli su un grafico noto come bussola politica. Successivamente, hanno testato se addestrare nuovamente i modelli con dati ancora più politicizzati modificasse il loro comportamento e la loro capacità di rilevare discorsi di odio e disinformazione (cosa che effettivamente è successa). Questa ricerca, che è stata premiata come miglior articolo alla conferenza dell’Association for Computational Linguistics il mese scorso, è descritta in un articolo sottoposto a revisione paritaria.
Dato che i language models dell’intelligenza artificiale vengono sempre più integrati in prodotti e servizi utilizzati da milioni di persone e poiché hanno il potenziale di causare danni reali, comprendere i presupposti e i bias politici sottostanti è di estrema importanza. Un chatbot che fornisce consulenza sanitaria potrebbe, ad esempio, rifiutarsi di offrire consigli sull’aborto o sulla contraccezione, mentre un bot del servizio clienti potrebbe iniziare a diffondere insulti offensivi.
Dopo il successo di ChatGPT, OpenAI ha ricevuto critiche da commentatori di destra che sostengono che il chatbot rifletta una visione del mondo più liberale. Tuttavia, la società afferma di stare lavorando per affrontare tali preoccupazioni, istruendo i suoi revisori umani (coloro che aiutano a perfezionare l’intelligenza artificiale) a non favorire alcun gruppo politico. “I bias che tuttavia possono emergere dal processo sopra descritto sono bug, non funzionalità”, afferma un post sul blog dell’azienda.
Chan Park, ricercatore PhD presso la Carnegie Mellon University e membro del gruppo di studio, non è d’accordo e afferma: “Crediamo che nessun language model possa essere completamente privo di bias politici”.
I bias si insinuano in ogni fase
Per comprendere come i language models dell’intelligenza artificiale rilevano i bias politici, i ricercatori hanno esaminato tre fasi di sviluppo di un modello.
Nella prima fase, hanno chiesto a 14 language models di concordare o meno con 62 affermazioni politicamente sensibili. Questo li ha aiutati a identificare le inclinazioni politiche alla base dei modelli e a tracciarle su una bussola politica. Con sorpresa del team, hanno scoperto che i modelli di intelligenza artificiale mostrano tendenze politiche nettamente diverse, afferma Park.
I ricercatori hanno scoperto che i modelli BERT, sviluppati da Google, erano socialmente più conservatori rispetto ai modelli GPT di OpenAI. A differenza dei modelli GPT, che predicono la parola successiva in una frase, i modelli BERT predicono parti di una frase utilizzando le informazioni circostanti all’interno di un testo. Nell’articolo, i ricercatori ipotizzano che il conservatorismo sociale dei modelli potrebbe derivare dal fatto che i vecchi modelli BERT sono stati addestrati su libri che tendevano ad essere più conservatori, mentre i modelli GPT più recenti sono addestrati su testi Internet più liberali.
Inoltre, è importante considerare che i modelli di intelligenza artificiale subiscono modifiche nel tempo, poiché le aziende tecnologiche aggiornano i loro set di dati e i metodi di addestramento. Ad esempio, GPT-2 ha manifestato sostegno alla “tassazione dei ricchi”, mentre il più recente GPT-3 di OpenAI non lo ha espresso.
Un portavoce di Meta ha affermato che la società ha rilasciato informazioni su come ha sviluppato Llama 2, incluso come ha perfezionato il modello per ridurre i bias, e che “continuerà a collaborare con la comunità per identificare e mitigare le vulnerabilità in modo trasparente, supportando così la creazione di un’intelligenza artificiale generativa più sicura”. Al momento della pubblicazione, Google non ha risposto alla richiesta di commento del MIT Technology Review.
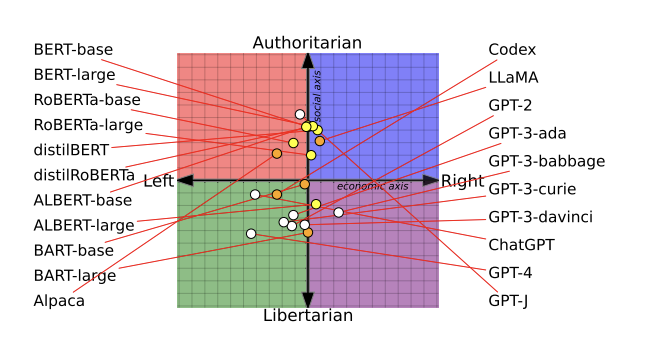
Il secondo passo prevedeva un ulteriore addestramento di due language models di intelligenza artificiale, GPT-2 di OpenAI e RoBERTa di Meta, utilizzando set di dati composti da media di notizie e dati dei social media provenienti da fonti sia di destra che di sinistra, come afferma Park. L’obiettivo del team era comprendere se i dati di addestramento influenzassero i bias politici.
E così è stato. Il team ha scoperto che questo processo ha contribuito a rafforzare ulteriormente i bias dei modelli: quelli già orientati a sinistra sono diventati ancora più di sinistra, mentre quelli orientati a destra sono diventati ancora più di destra.
Nella terza fase della ricerca, il team ha riscontrato notevoli differenze nel modo in cui le inclinazioni politiche dei language models influenzano il tipo di contenuti che i modelli classificano come incitamento all’odio e disinformazione.
I modelli addestrati con dati di orientamento politico di sinistra si sono dimostrati più sensibili all’incitamento all’odio nei confronti delle minoranze etniche, religiose e sessuali negli Stati Uniti, come ad esempio le persone di colore e LGBTQ+. Al contrario, i modelli addestrati con dati di orientamento politico di destra hanno mostrato una maggiore sensibilità all’incitamento all’odio contro gli uomini cristiani bianchi.
Inoltre, i modelli di orientamento politico di sinistra sono risultati migliori nell’identificare la disinformazione proveniente da fonti di destra, ma meno sensibili alla disinformazione proveniente da fonti di sinistra. I modelli di orientamento politico di destra hanno mostrato il comportamento opposto.
Ottenere dei dataset privi di bias non è abbastanza
In definitiva, è impossibile per gli osservatori esterni comprendere perché diversi modelli di intelligenza artificiale presentino bias politici diversi, in quanto le aziende tecnologiche non divulgano i dettagli dei dati o dei metodi utilizzati per addestrarli, come afferma Park.
Una strategia che i ricercatori hanno tentato per mitigare i bias nei language models è stata la rimozione dei contenuti di parte dai set di dati o il loro filtraggio. “La grande domanda che il documento solleva è: la pulizia dei dati dai bias è sufficiente? E la risposta è no”, dichiara Soroush Vosoughi, assistente di un professore di informatica al Dartmouth College, non coinvolto nello studio.
Vosoughi sottolinea che è estremamente difficile eliminare completamente i bias da un vasto database e che i modelli di intelligenza artificiale possono anche mettere in luce bias di basso livello presenti nei dati.
Una limitazione dello studio è stata la capacità dei ricercatori di condurre la seconda e la terza fase solo con modelli relativamente vecchi e piccoli, come GPT-2 e RoBERTa, come spiega Ruibo Liu, ricercatore presso DeepMind, che ha studiato i bias politici nei language models dell’intelligenza artificiale ma non ha partecipato alla ricerca.
Liu esprime il desiderio di vedere se le conclusioni del documento si applicano anche ai modelli di intelligenza artificiale più recenti. Tuttavia, gli accademici non hanno, né probabilmente avranno, accesso ai dettagli interni dei sistemi di intelligenza artificiale di punta come ChatGPT e GPT-4, il che rende l’analisi più complessa.
Un’altra limitazione è che se i modelli di intelligenza artificiale si limitano a generare risposte, come spesso accade, queste potrebbero non riflettere accuratamente il loro “stato interno”, come sottolinea Vosoughi.
I ricercatori ammettono anche che il test della bussola politica, sebbene ampiamente utilizzato, non è un metodo perfetto per misurare tutte le sfumature politiche.
Con l’integrazione sempre più diffusa di modelli di intelligenza artificiale nei prodotti e nei servizi aziendali, è fondamentale che le aziende siano consapevoli di come tali bias influenzino il comportamento dei loro modelli al fine di renderli più equi, conclude Park: “Non c’è equità senza consapevolezza”.
Heikkilä M., (2023, August 7), AI language models are rife with political biases, MIT Technology Revie , www.technologyreview.com.
Vi aspettiamo al prossimo workshop gratuito per parlarne dal vivo insieme a Simone Rizzo!
Clicca qui per registrarti!
Non perderti, ogni mese, gli approfondimenti sulle ultime novità in campo digital! Se vuoi sapere di più, visita la sezione “Blog“ sulla nostra pagina!
Leave a comment