Getting started
To run the Cheshire Cat, you need to have docker (instructions) and docker-compose (instructions) installed on your system.
- Create and API key on the language model provider website
- Start the app with docker-compose up inside the repository
- Open the app in your browser at localhost:1865/admin
- Configure a LLM in the Settings tab and paste you API key
- Start chatting
You can also interact via REST API and try out the endpoints on localhost:1865/docs
The first time you run the docker-compose up command it will take several minutes as docker images occupy some GBs.
Quickstart
Here is an example of a quick setup running the gpt3.5-turbo OpenAI model.
Create an API key with + Create new secret key in your OpenAI personal account, then:
Download the code:
git clone https://github.com/cheshire-cat-ai/core.gitCode language: PHP (php)Enter the folder
cd coreRun docker containers
docker compose upWhen you’re done using the Cat, remember to CTRL+c in the terminal and docker-compose down.
GUI setup
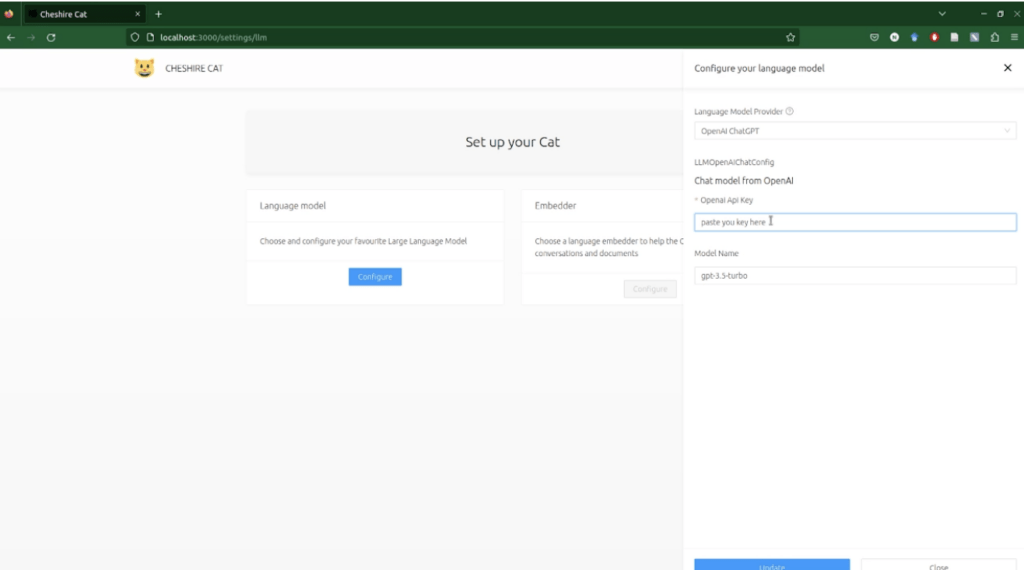
Update
The project is still a work in progress.
If you want to update it run the following, one command (line) at a time:
cd core
git pull
docker compose build --no-cache
docker rmi -f $(docker images -f "dangling=true" -q)
docker compose upCode language: JavaScript (javascript)How the Cat works
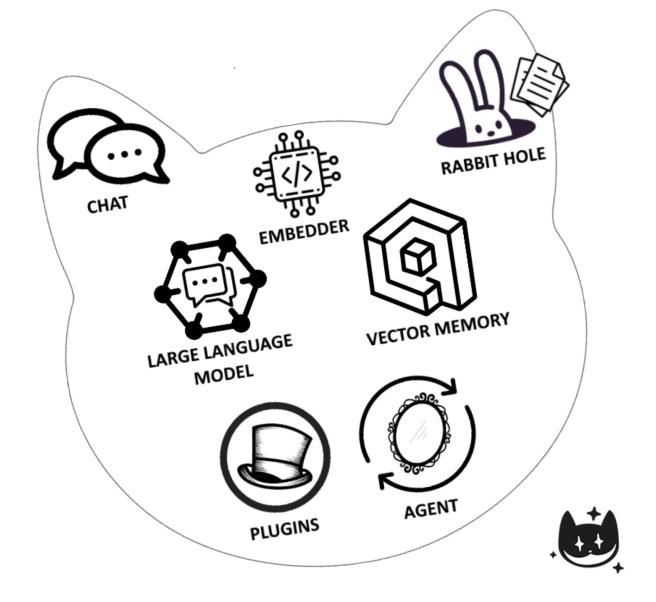
Components
The Cheshire Cat is made of many pluggable components that make it fully customizable.
💬 Chat
This is the Graphical User Interface (GUI) component that allows you to interact directly with the Cat. From the GUI, you can also set the language model you want the Cat to run.
🕳️ Rabbit Hole
This component handles the ingestion of documents.Files that are sent down the Rabbit Hole are split into chunks and saved in the Cat’s declarative memory to be further retrieved in the conversation.
🗣️ Large Language Model (LLM)
This is one of the core components of the Cheshire Cat framework. A LLM is a Deep Learning model that’s been trained on a huge volume of text data and can perform many types of language tasks. The model takes a text string as input (e.g. the user’s prompt) and provides a meaningful answer. The answer consistency and adequacy is enriched with the context of previous conversations and documents uploaded in the Cat’s memory.
📈 Embedder
The embedder is another Deep Learning model similar to the LLM. Differently, it doesn’t perform language tasks. The model takes a text string as input and encodes it in a numerical representation. This operation allows to represent textual data as vectors and perform geometrical operation on them. For instance, given an input, the embedder is used to retrieve similar sentences from the Cat’s memory.
🧠 Vector Memory
As a result of the Embedder encoding, we get a set of vectors that are used to store the Cat’s memory in a vector database. Memories store not only the vector representation of the input, but also the time instant and personalized metadata to facilitate and enhance the information retrieval. The Cat embeds two types of vector memories, namely the episodic and declarative memories. The formers are the things the human said in the past; the latter the documents sent down the Rabbit hole.
🤖 Agent
This is another core component of the Cheshire Cat framework.The agent orchestrates the calls that are made to the LLM. This component allows the Cat to decide which action to take according to the input the user provides. Possible actions range from holding the conversation to executing complex tasks, chaining predefined or custom tools.
🧩 Plugins
These are functions to extend the Cat’s capabilities. Plugins are a set of tools and hooks that allow the Agent to achieve complex goals. This component let the Cat assists you with tailored needs.
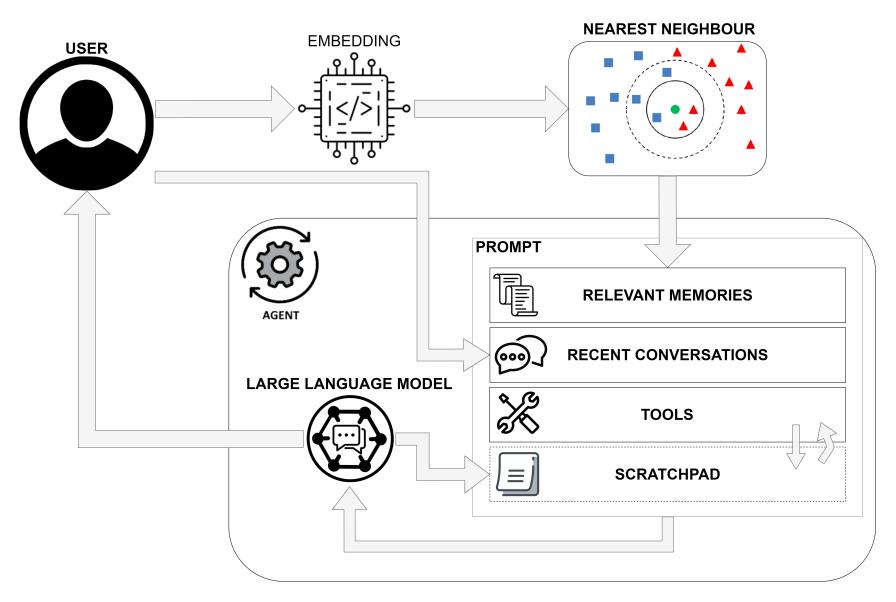
Main loop
Questo articolo è stato scritto da Piero Savastano.
Vi aspettiamo al prossimo workshop gratuito per parlarne dal vivo insieme a Piero Savastano!
Clicca qui per registrarti!
Non perderti, ogni mese, gli approfondimenti sulle ultime novità in campo digital! Se vuoi sapere di più, visita la sezione “Blog“ sulla nostra pagina!